RDBMS(Relational Database Management System) 의 내부 구조 (쿼리는 어떻게 실행되는가)
29 Oct 2020
Reading time ~4 minutes
이 글은 Architecture of Database System 의 개요 부분을 번역, 정리한 글입니다.
Overview
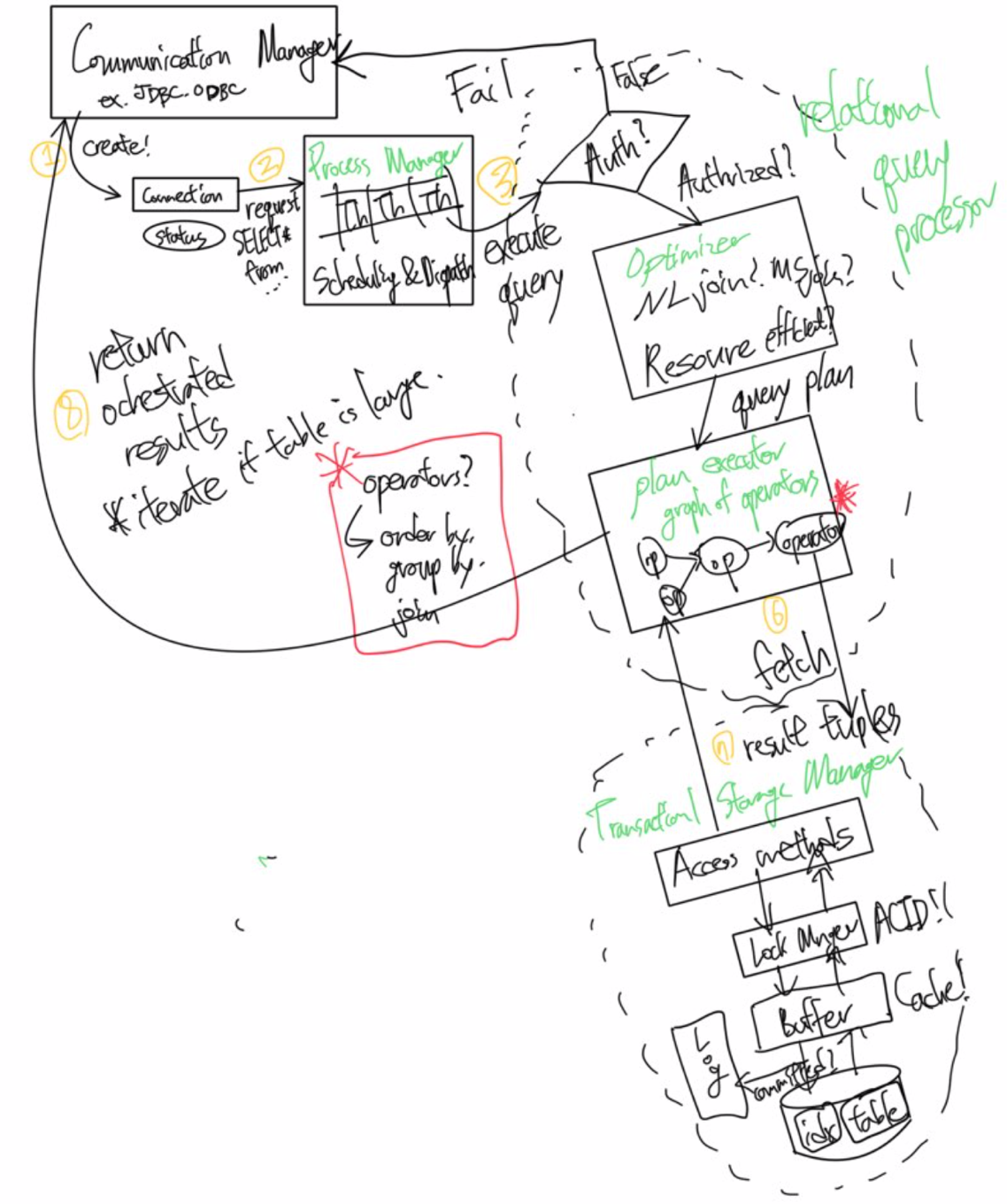
앞으로 설명할 RDBMS 구조에 대한 그림입니다.
구성 요소
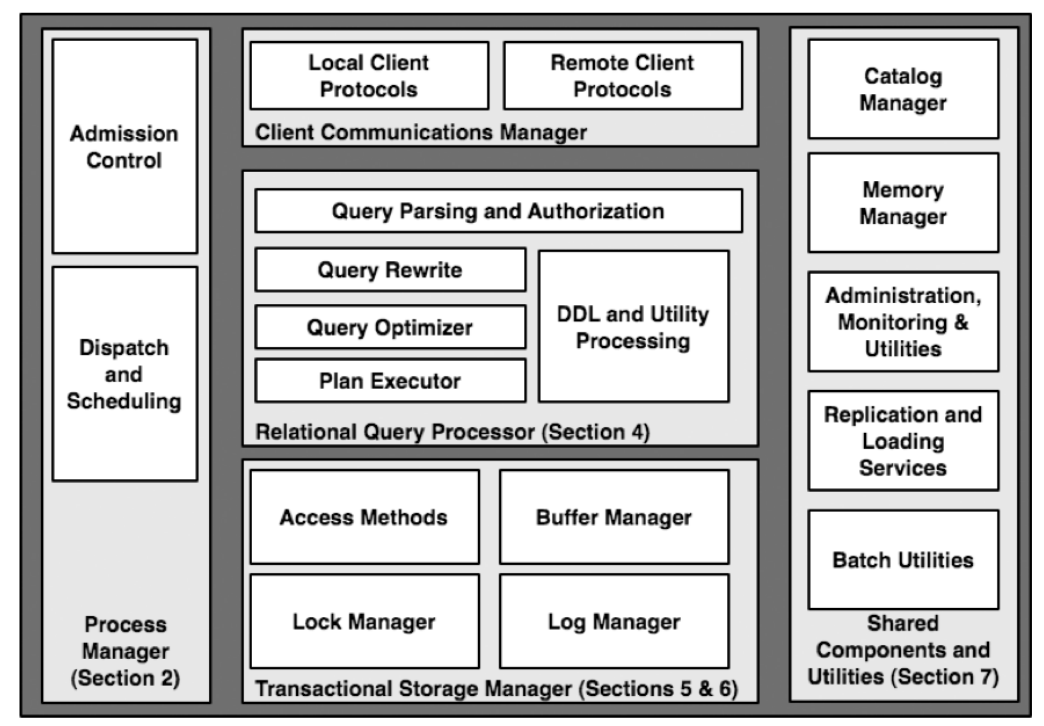
일반적인 RDBMS에는 위 그림과 같이 다섯개의 주요 컴포넌트들이 있습니다. 이 컴포넌트들이 어떻게 함께 작동하는지 데이터베이스 시스템 내의 쿼리의 흐름을 따라가봅시다. 공항에 있는 일반적인 DB 상호작용의 간단한 예시를 한번 생각해보면, gate 에이전트가 비행기의 승객 목록을 요청을 보내기 위한 form을 클릭한다고 해봅시다. 이는 대략 다음과 같은 하나의 쿼리 트랜잭션의 흐름을 발생시킬 것입니다.
쿼리 실행 흐름
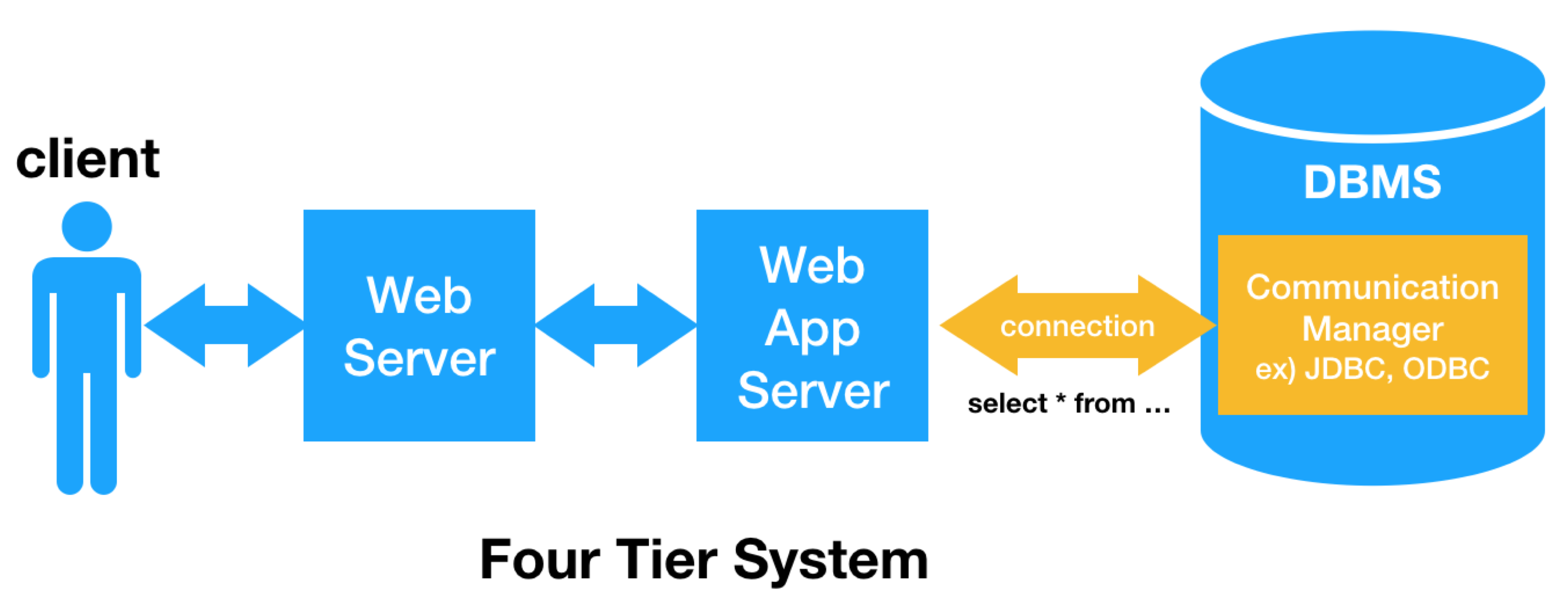
그림: Four Tier System. Web App Server가 없으면 Three tier, Web Server, Web App Server 없이 DBMS와 클라이언트가 직접 연결되면 Two Tier System이다.
- 먼저 airport gate에 있는 PC(Client)가 네트워크를 거쳐 Client Communication Manager를 통해 connection을 하나 생성하는 API를 호출합니다. client와 DB server가 직접적으로 연결된 케이스가 있을거고(예를 들면 ODBC나 JDBC 연결 프로토콜 같은), 이러한 방식은 two-tier 혹은 client-server 시스템이라고 불립니다. 다른 케이스로는 middle-tier server를 연결하는 경우가 있는데, client와 DBMS사이의 연결을 우회하기 위한 프로토콜을 사용할것이고, 이를 three-tier 시스템이라고 부른다. 많은 웹기반 시나리오들은 웹서버와 DBMS 사이에 어플리케이션 서버를 두는데, 이를 four tier라 합니다. 이런 다양한 옵션이 있는데, 일반적인 DBMS는 수많은 다른 연결 프로토콜과 호환 가능해야 합니다. 하지만 기본적으로 모든 프로토콜에 해당하는 DBMS client Communication Manager의 역할은 대개 동일합니다: 요청자의 연결 상태를 기억하고 연결을 맺는것, 호출자(caller)에게 SQL 명령어를 응답하는 것, 데이터와 제어 메세지(결과 코드, 에러 등)들을 적절하게 반환하는 것 등. 예제에서, Communication Manager는 클라이언트의 보안 자격 증명들을 설정하고 새 커넥션의 상세 내용을 기억하기 위한 상태와 현재 SQL 문을 설정합니다. 그리고 그 첫번째 요청은 DBMS의 더 깊은 부분으로 전달됩니다.
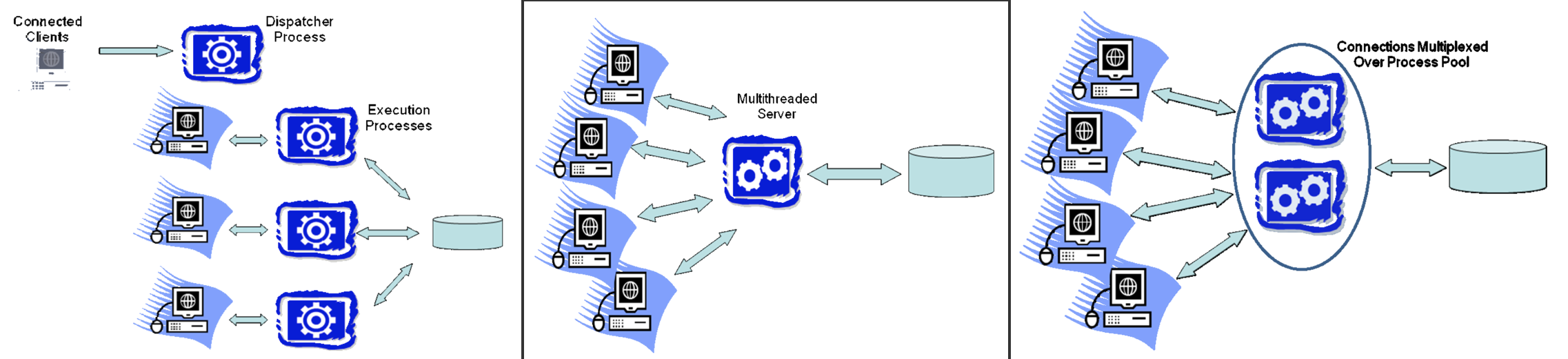
그림: RDBMS가 프로세스/스레드를 해당 command에 할당하는 방법. (왼쪽부터 오른쪽 그림에 대한 설명) 초기 DBMS worker 모델: 워커와 OS 프로세스가 1:1 매핑. 구현이 단순. but 메모리 오버헤드. 각각의 워커가 OS 스레드. race condition 제어. 프로세스 풀중에서 하나를 worker에 할당. 프로세스를 재사용하기 때문에 프로세스 생성/삭제 오버헤드 제거.
- SQL문을 받고나면, DBMS는 스레드를 command에 할당해야합니다. 이는 반드시 스레드의 데이터와 제어 출력값이 Communications Manager를 통해 클라이언트에 연결되어 있다는 것을 보장해야 합니다. 이는 DBMS Process Manager(그림의 왼쪽 부분)의 역할입니다. DBMS가 쿼리 내에서 이 단계에서 내려야하는 가장 중요한 결정은 Admission control(제어 승인)과 관련되어 있습니다 (시스템이 그 쿼리를 즉시 처리해야하는지, 이 쿼리에 사용되는 충분한 리소스가 사용가능 해질 때까지 실행을 연기해야 하는지 등. 예를 들면 메모리가 부족해서 쿼리를 즉시 처리할 수 없을수도 있다.)
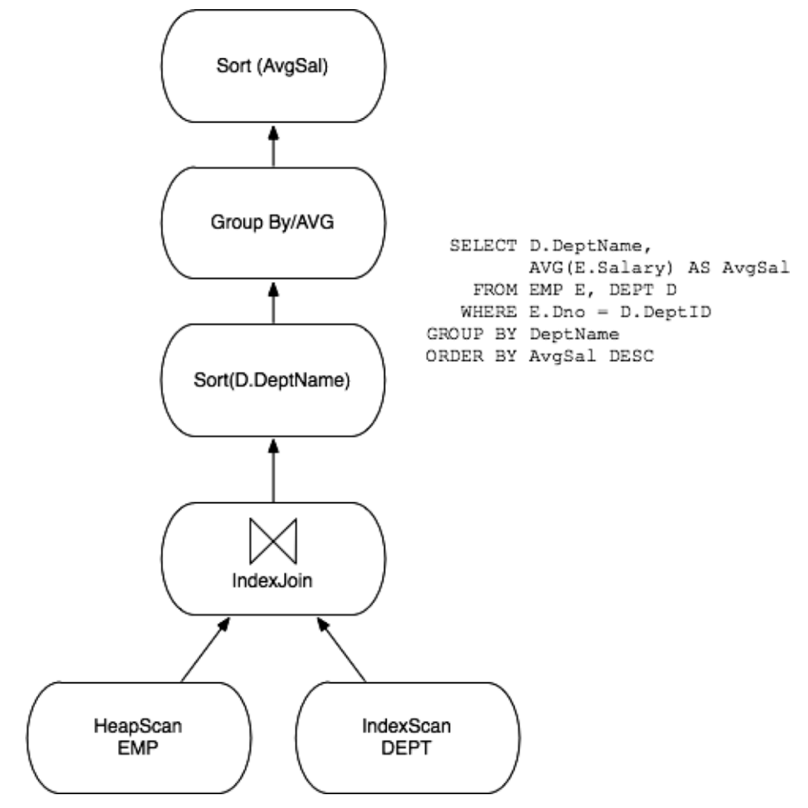
그림: 쿼리 플랜의 예시(a graph of operators)
-
한번 제어 스레드가 할당되어서 전송되고 나면, gate agent의 쿼리는 실행 가능하게 되고 Relational Query Processor(Optimizer, Query rewriter, …) 에 있는 코드를 호출해서 이를 실행합니다. 이 모듈들은 유저가 쿼리를 실행할 권한이 있는지 체크하고, 유저의 SQL 쿼리 텍스트를 내부의 query plan으로 컴파일합니다. 컴파일이 한번 되고나면, 결과 query plan은 plan executor를 통해서 제어됩니다. plan executor는 어떤 query를 실행하기 위한 operator들의 집합입니다. 보통 operator들은 조인, selection, projection, aggregation, sorting 같은 Relation query 처리 임무를 구현하고, 시스템의 더 낮은 레이어로부터 data record들을 요청합니다. 저희 예제에서는 gate agent’s의 쿼리의 결과를 내기 위해서 operator들의 작은 집합들이 쿼리 최적화 프로세스에 의해 조합(assemble)됩니다.
-
Gate agent의 쿼리 플랜의 기저에는, 데이터베이스에서 데이터를 요청하기 위해 하나 이상의 operators 가 존재합니다. 이런 operators는 모든 데이터 접근(read)과 조작(create, update, delete) 요청들을 관리하는 DBMS Transaction Storage Manager로 부터 데이터를 가져오는 요청을 만듭니다. Storage System은 디스크의 데이터에 접근하고 organizing 하기 위한 자료구조와 알고리즘들이 포함됩니다. 또한 데이블이나 인덱스 같은 기본적인 구조들도 포함됩니다. 그리고 언제 그리고 어떤 데이터가 디스크와 메모리 버퍼 사이에 전송될지 결정하는 buffer management 모듈도 포함됩니다. 다시 예제로 돌아와서, 접근 메서드 내의 데이터 접근 과정 내에, gate agent의 쿼리는 트랜잭션의 ACID 속성을 만족하기 위해서 반드시 트랜잭션 관리 코드를 수행해야합니다. 데이터 접근 전에, 다른 동시 쿼리에 대해 올바른 실행을 보장하기 위해 Lock 관리자에서 Lock을 획득합니다. 만약에 gate agent의 쿼리가 데이터베이스를 업데이트 한다면, commit 되면 log manager를 사용해서 durable하게 하고 만약 abort되면 전부 취소 시킵니다.
-
이 시점에서 예제의 쿼리는, data record를 접근하기 시작했었고, 클라이언트에게 결과를 주기 위한 준비가 되었습니다. 이제 지금까지 설명했던 것들이 “unwinding the stack” 됩니다. 접근 메서드는 DB 데이터로부터 결과 튜플들의 계산 결과를 orchestrate하는 쿼리 executor의 operators에 제어권을 반환하고, 결과 튜플이 생성된 것은 Communication manager를 위해서 버퍼에 위치하고, 요청자에게 결과 값을 다시돌려줍니다. 커다란 결과 셋트인 경우, 클라이언트는 보통 communations manager, query executor, storage manager를 통해 여러번의 순환을 거친 결과 쿼리를 점진적으로 더 데이터를 가져오도록 추가적인 요청을 만듭니다. 예제에서, 쿼리의 마지막에는 트랜잭션이 완료되고 connection이 닫힙니다. 트랜잭션의 상태를 지우는 트랜잭션 매니저, 쿼리의 제어 구조를 해제 하는 프로세스 매니저, 커넥션에 대한 커뮤니케이션 상태를 지우는 모든 결과들을 지웁니다.
-
이 예제에서 RDBMS의 많은 주요 컴포넌트들을 살펴보았지만, 이게 전부는 아닙니다. 그림 오른쪽 부분에 DBMS의 모든 중요한 컴포넌트들과 유틸리티들이 있습니다. 그 카탈로그와 메모리 매니저들은 어떤 트랜잭션이 실행되는 동안 유틸리티로서 호출이 되며, 그 카탈로그들은 인증, 파싱, 쿼리 최적화를 하는 동안 쿼리 프로세서에 의해서 사용이 됩니다. 메모리 매니저는 메모리가 동적으로 할당되거나 해제될 필요가 있을때마다 DBMS를 통해서 사용됩니다. 그림에 오른쪽 박스 표현된 나머지 모듈들은 특정 쿼리의 독립적으로 작동되는 유틸들이며, DB를 전체적으로 조절하고 신뢰성 있도록 해주는 유틸이기도 합니다.
출처
- https://www.labouseur.com/courses/db/papers/fntdb07-architecture.pdf