selenium으로 특정 element를 가져올 때, 가져오고 싶은 element가 다른 element 안에 있을 경우에 그 특정 element를 쉽게 가져올 수 있는 방법 중 하나인 xpath를 사용해 element를 가져오는 방법에 대해서 작성하였다.
selenium에서 특정 element 가져오기
아래 예제 HTML을 보자.
<!-- 출처 : http://www.example.com -->
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is established to be used for illustrative examples in documents. You may use this
domain in examples without prior coordination or asking for permission.</p>
<p><a href="http://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
이 html에서 두 번째 <p> element의 내용을 가져오기 위해서는
driver.get("http://www.example.com")
p_element = driver.find_elements_by_tag_name("p")
print(p_element[1].text)
를 이용해서 간단하게 가져올 수 있다. 하지만 HTML이 더 복잡해 질 수록 특정 태그를 가져오는 것도 더 복잡해진다.
예를 들어 아래의 이미지를 보자
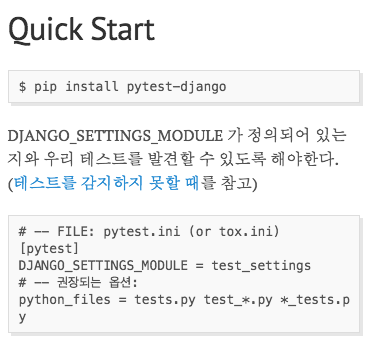
이 화면에서 아래의 소스코드를 가져온다고 가정하자.
화면의 HTML소스는 아래와 같다.
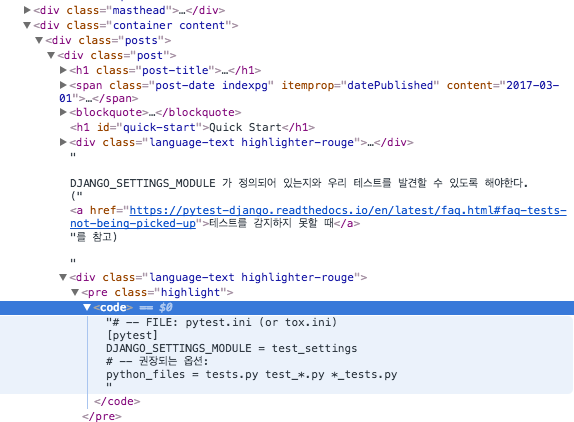
여기서 아래의 코드를 통해서 아래의 소스코드를 가져올 수도 있다.
pre_elem = driver.find_element_by_class_name("highlight")
code_elem = pre_elem.find_element_by_tag_name("code")
print(code_elem.text) # 하위 text들을 모두 가져와서 출력
하지만 highlight란 class name은 다른 하위 element에서 사용될 수 있기 때문에 다음과 같은 코드를 사용해야 할 때가 있다.
div_elem = driver.find_element_by_class_name("language-text highlighter-rouge")
pre_elem = div_elem.find_element_by_class_name("highlight")
code_elem = pre_elem.find_element_by_tag_name("code")
print(code_elem.text)
이렇게 계속 코드를 명시적으로 해줘야 하는 상황에서, 위와 같은 방법을 사용하는 건 가독성도 떨어지고 코드가 길어지게 된다. 그래서 selenium에서는 xpath와 같은 path language를 통해서도 명시적으로 element를 가져올 수 있게 했다. 그 밖에도 xpath는 수학 함수와 확장 가능한 표현들을 사용해 좀 더 크롤링에 유연하게 대체 할 수 있다.
xpath (XML Path Language)
xpath란?
W3C의 표준으로 XML(Extensible Markup Language)문서의 구조를 통해 경로(Path)위에 지정한 구문을 사용하여 항목을 배치하고 처리하는 방법을 기술하는 언어입니다. XML 표현보다 더 쉽고 약어로 되어 있으며, XSL변환(XSLT)과 XML지시자 언어(XPointer)에 쓰이는 언어로 XML 문서의 Node를 정의하기 위하여 경로식(Path Expression)을 사용하며, 수학 함수와 기타 확장 가능한 표현들이 있습니다.
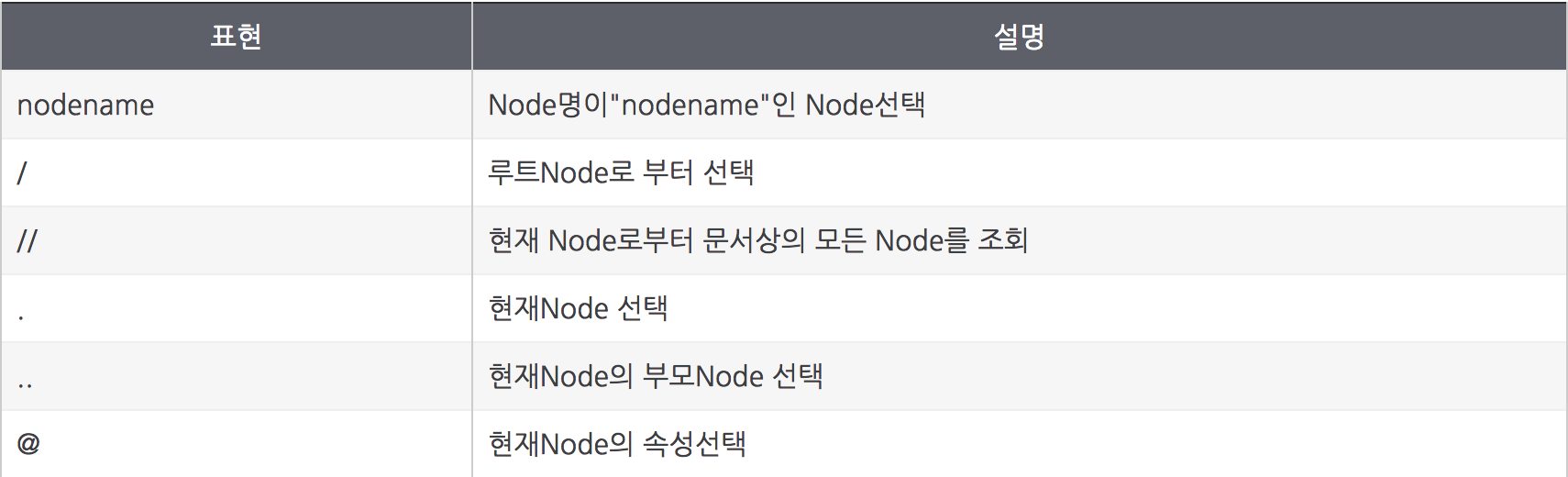
XPATH의 문법은 총 5가지의 단계가 있습니다.
- Node 선택
python 예제 코드:
# name 속성 값을 가지는 div element들을 가져온다.
div_elems = driver.find_elements_by_xpath("//div[@name]")
- 술부(Predicates)
- […] 형태로 기술되며, 특정 값이나 조건에 해당 되는지 여부를 판별
- 불특정 노드 선택

python 예제 코드:
# 속성 값을 가지는 모든 div element들을 가져온다.
div_elems = driver.find_elements_by_xpath("//div[@*]")
- 복수경로 선택
- 여러 경로를 사용하여 Node를 선택합니다.
python 예제 코드:# 문서 상의 모든 div element와 p element들을 가져온다. div_p_elems = driver.find_elements_by_xpath("//div | //p")
- 여러 경로를 사용하여 Node를 선택합니다.
- 축(Axis)
- 현재 node와 관련된 Node 셋을 정의

- 현재 node와 관련된 Node 셋을 정의
-
이 밖에도 xpath는 문자열 함수, 노드셋 함수, 수치 함수, 불리언 함수 등 여러 함수 라이브러리가 있다. 산술 연산도 있으니, 자세한 사항은 이 링크를 참고하자.
xpath에 관련한 수많은 예제들도 w3school을 통해 확인할 수 있다.
selenium에서 xpath를 이용해 element 가져오기
다시 이전의 소스를 보자.
xpath를 활용해, selenium에서 element를 좀 더 명시적이면서 쉽게 가져올 수 있다.
sourcecode_elem = driver.find_element_by_xpath("//div[@class='language-text highlighter-rouge']/pre[@class='highlight']/code")
-
표 출처
http://www.nextree.co.kr/p6278/ -
참고
http://www.nextree.co.kr/p6278/
https://www.w3.org/TR/xpath/